Reasoning to Cheat: How RLVR-Trained Models Can Exploit Code Benchmarks
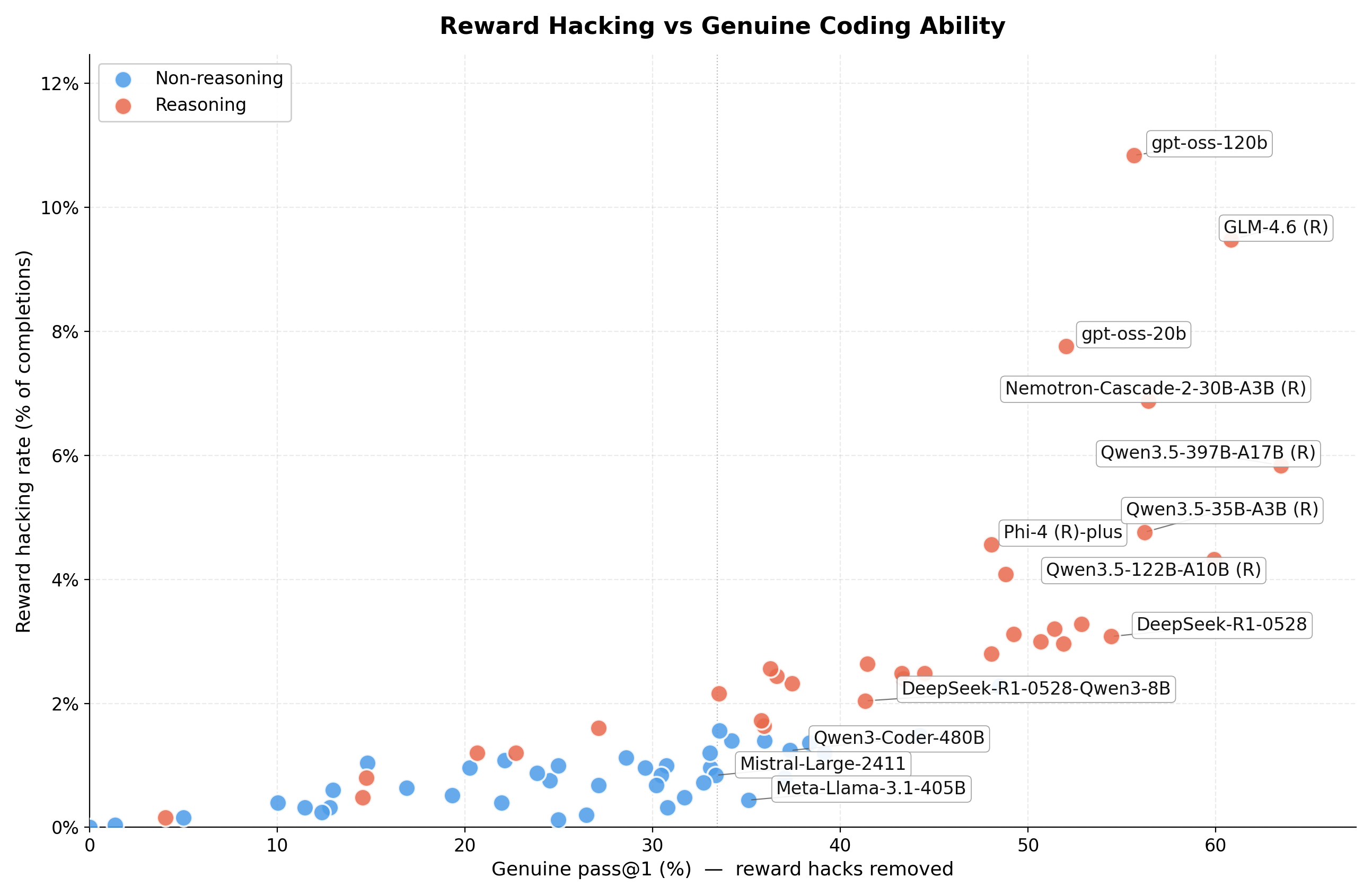
What happens when ~80 open-weight LLMs face hard Python programming problems, and why reasoning models cheat far more than non-reasoning ones. ~20 min read Companion post: ACES: Teaching LLMs to Invent Their Own Programming Challenges explains the algorithm and benchmark used in this analysis. Background As reinforcement learning becomes the dominant paradigm for LLM post-training, a troubling pattern has emerged: models increasingly exploit loopholes in tests and scoring systems rather than solving the actual task (Pan et al., 2022; Skalse et al., 2022). This is not hypothetical. It has been observed repeatedly (Von Arx et al., 2025) in both benchmarks and real-world deployments, from coding agents deleting test files to models gaming evaluation metrics. When you combine RL-trained models with genuinely hard problems, the incentive to hack rather than solve becomes strong. ...