Self-Improving Language Models for Evolutionary Program Synthesis: A Case Study on ARC-AGI
🤗 Hugging Face (data and model) | 📑 Paper | 📑 Blog
Large Language Models (LLMs) have become incredibly powerful, but they often hit a wall when faced with truly complex reasoning tasks that require discovering a solution from scratch. Simply throwing more computing power or using a bigger model often yields diminishing returns. But what if a model could learn from its own experience, getting smarter with every attempt?
We introduce a framework called SOAR (Self-improving Operators for Automated program Refinements) that does just that. By creating a “virtuous cycle” of evolutionary search and learning, SOAR enables AI models to bootstrap their own capabilities and solve problems previously beyond their reach. we tested SOAR on the Abstraction and Reasoning Corpus (ARC-AGI-1), a notoriously difficult benchmark designed to challenge an AI’s core reasoning abilities. We show that using SOAR with only open weight LLM, we can significantly outperforming much larger closed source LLMs.
The Challenge: The AI Reasoning Wall
Program synthesis is the task of automatically generating a computer program that meets a user’s specifications. For simple tasks, an LLM can often produce a working solution in a single attempt. However, for complex problems like those in the ARC benchmark, this is nearly impossible.
The ARC benchmark consists of visual puzzles where you must figure out the underlying logical transformation from a few input-output examples and then apply it to a new test input. These tasks require concepts like object permanence, arithmetic, and spatial reasoning, making them surprisingly difficult for current AI. For instance, even powerful models like GPT-4.1 and Claude-4-Sonnet could only solve 8% and 20.75% of the test tasks, respectively, in a single shot.
While search-based methods, which generate and test many potential solutions, improve performance, they are ultimately limited by the fixed capabilities of the base LLM. This creates a performance plateau that can’t be overcome by simply running more searches.
SOAR’s Solution: A Virtuous Cycle of Self-Improvement
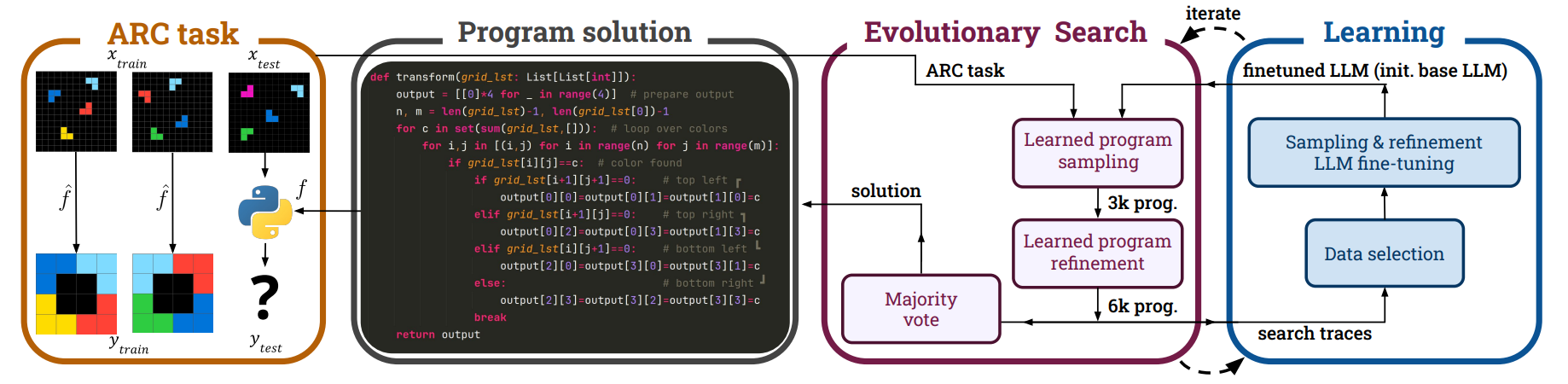
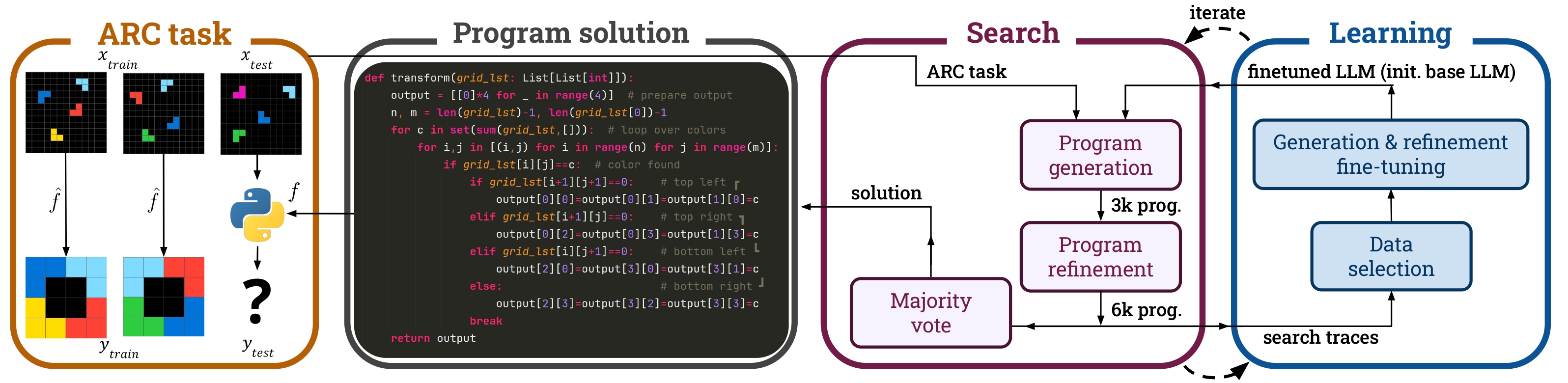
SOAR overcomes this limitation by making the LLM itself part of a learning loop. The system alternates between two key phases:
-
Evolutionary Search (Sample & Refine): SOAR uses an LLM to generate an initial pool of thousands of candidate programs (the “sampling” step). It then tests these programs and uses the LLM again to intelligently modify or “refine” the most promising ones based on their performance.
-
Learning from Hindsight: SOAR takes all the programs generated during the search phase—including both successes and failures—and uses them as training data. The key insight is that any failed program is simply a correct program for a different task. By “relabeling” these failed attempts as correct solutions for the synthetic tasks they inadvertently solve, SOAR creates a diverse dataset to learn from.
This process creates a powerful feedback loop: the fine-tuned model becomes better at sampling and refining, which leads to a more effective search in the next iteration, which in turn generates even better training data. And unlike previous approaches that rely on human-engineered domain-specific languages or human-generated solutions, SOAR learns to synthesize programs in Python solely from its own synthesis attempts, encompassing both successes and failures.
Breaking the Scaling Plateau
The improvements driven by SOAR are dramatic. We tested our framework using multiple model (Qwen-2.5-Coder-(7/14/32B), Qwen-2.5-72B and Mistral-Large-2), SOAR broke through performance ceilings that limit methods based on fixed models.
- Massive Performance Gains: After several iterations, SOAR nearly doubled the search performance for all tested models. By combining the solutions from all its models, SOAR ultimately solved 80% of the public ARC train set and 52% of the public ARC test set, a state-of-the-art result for methods using open-source LLMs without any hand-crafted data.
- Smaller Models Outperform Giants: SOAR’s self-improvement allows smaller, more efficient models to punch far above their weight. After its training iterations, SOAR’s 14-billion-parameter model achieved 42.75% accuracy, outperforming the one-shot performance of closed-source models like GPT-4.1 and the 33% score of 03-mini.
- Learning on the Job: SOAR features a “test-time training” mechanism that allows it to continue improving on new problems even without access to ground-truth solutions.
- Synergy in Learning: We found that jointly training the model on both the sampling and refinement tasks yielded the best results, indicating a positive synergy where learning to generate programs helps with refining them, and vice-versa.
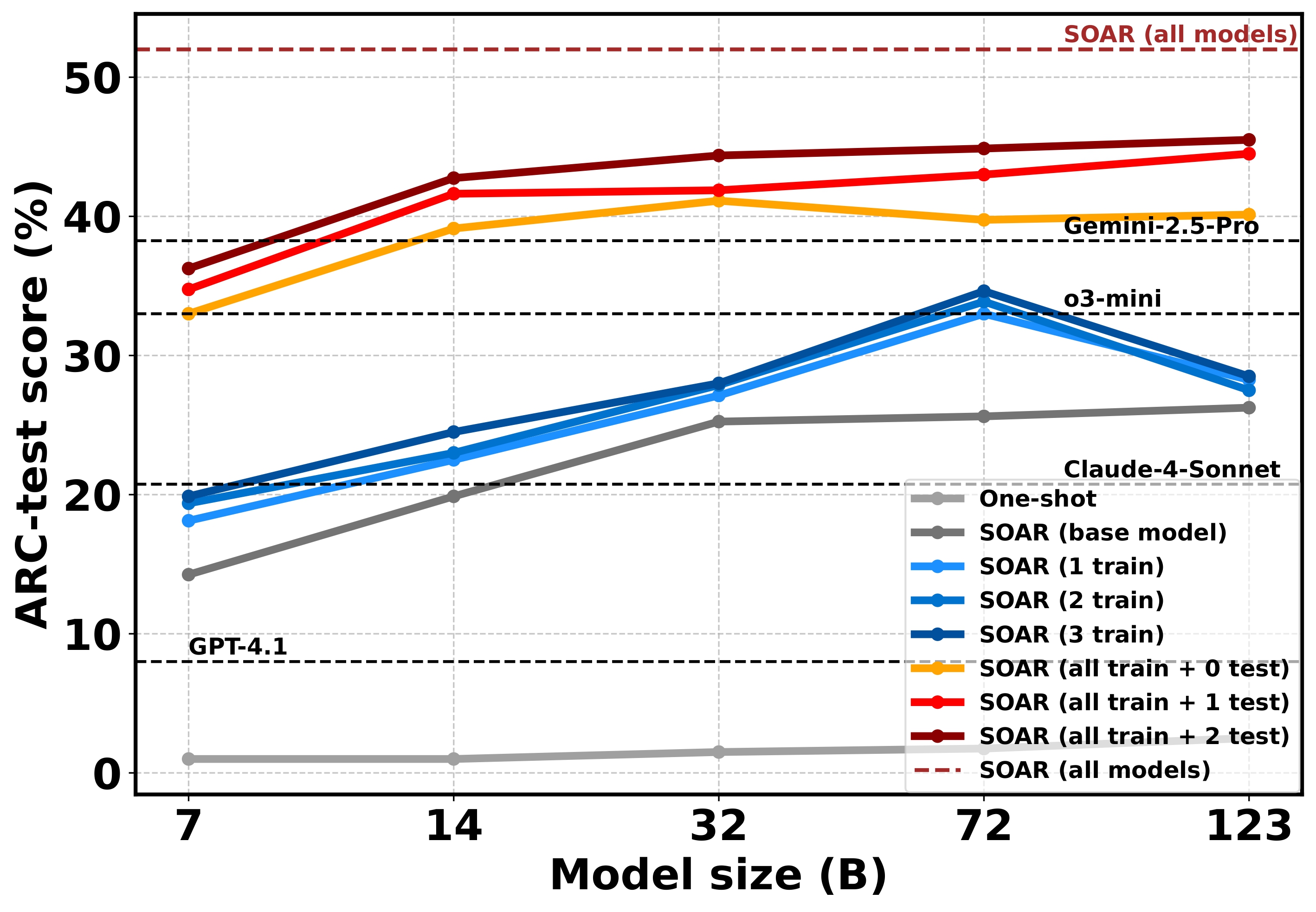 Figure 1. Performance plateaus with increasing model size when using fixed sampling and refinement capabilities (SOAR (base-model)). In contrast, SOAR progressively lifts the scaling curves across iterations, enabling smaller models to match or outperform much larger ones.
Figure 1. Performance plateaus with increasing model size when using fixed sampling and refinement capabilities (SOAR (base-model)). In contrast, SOAR progressively lifts the scaling curves across iterations, enabling smaller models to match or outperform much larger ones.
Note: Only the 7B, 14B, and 32B models are from the same family (Qwen-2.5-Coder); 72B is from the Qwen-2.5 family, and 123B is Mistral-large-2407. One-shot results for closed-source LLMs are shown (sampled once).
Why This Matters
SOAR demonstrates that a path to more capable AI may not lie just in building ever-larger models, but in creating systems that can learn and improve autonomously from their own experience.
By overcoming the performance plateaus associated with model size and compute budget, SOAR presents a new paradigm for AI development. Its framework could potentially serve as a “drop-in upgrade” for other advanced framework that currently uses a frozen LM (e.g., FunSearch, AlphaEvolve, …), enabling them to continually learn from their own search traces.
Want to dig deeper?
Check out the full paper and explore the data as we have released a dataset containing 5 million ARC solutions. For solutions that successfully solve an original ARC task, we deduplicate entries by their code to ensure uniqueness. For solutions that correspond to new synthetic tasks generated via hindsight relabeling, we deduplicate based on their output results. This approach ensures a diverse and high-quality dataset for further research and development.
Model:
Paper:
Self-Improving Language Models for Evolutionary Program Synthesis: A Case Study on ARC-AGI
Julien Pourcel, Cédric Colas, Pierre-Yves Oudeyer. Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025.